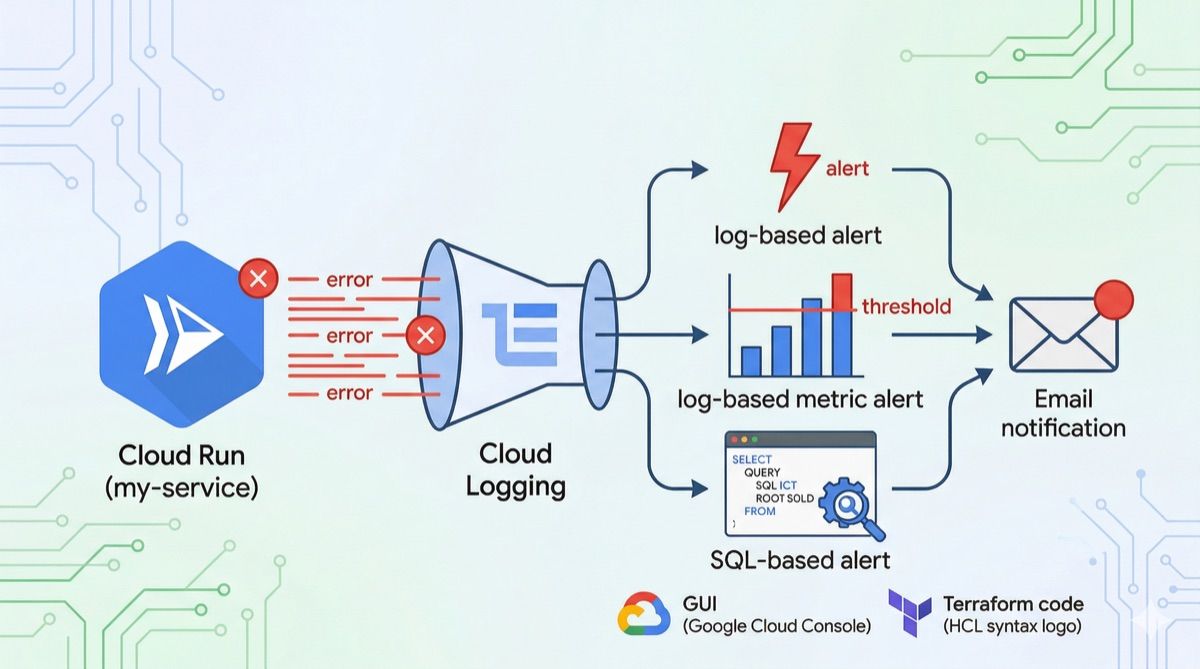
Cloud Logging のアラートポリシーを活用して Cloud Run を監視しよう
はじめに
Cloud Run でサービスを運用していると、「エラーが起きていたのに気づかなかった」という経験はないでしょうか。ログを毎日目視で確認するのは現実的ではありませんし、障害の検知が遅れればユーザーへの影響も大きくなります。
Google Cloud には Cloud Logging と連携したアラートポリシーの仕組みがあり、特定の条件に合致するログが発生した際に自動で通知を受け取ることができます。実はこのアラートポリシーには3種類の方式があり、それぞれ得意な場面が異なります。
本記事では、Cloud Run を題材に、3種類のアラートポリシーの特徴と設定方法を Google Cloud コンソール(GUI)と Terraform の両面から解説します。
Cloud Logging のアラートポリシーとは
Cloud Logging では、以下の3種類のアラートポリシーを利用できます。
| 種類 | トリガー条件 | ユースケース | 特徴 |
|---|---|---|---|
| ログベースのアラート | 特定のログエントリが出現 | セキュリティイベント、重大エラーの即時検知 | シンプル、即時性が高い |
| ログベースの指標アラート | ログから作成した指標が閾値を超過 | エラー率の監視、一定期間の集計 | 統計的、柔軟な閾値設定 |
| SQL ベースのアラート | SQL クエリの結果 | 複雑なパターン分析、複数ログの結合 | 高度な分析が可能 |
簡単に言えば、「このエラーが出たらすぐ知りたい」ならログベース、「5分間にエラーが10件以上なら知りたい」なら指標ベース、「複雑な条件で集計して判定したい」なら SQL ベースが適しています。
事前準備:通知チャンネルの設定
アラートポリシーを作成する前に、通知先となるチャンネルを設定しておきましょう。ここではメール通知を設定します。
コンソールでの設定
- Google Cloud コンソールで Monitoring > アラート を開く
- 上部の「通知チャンネルを編集」をクリック
- Email の「ADD NEW」からメールアドレスと表示名を登録
- テスト通知を送信して、正しく届くことを確認
Tips: メール以外にも Slack、PagerDuty、Webhook など多数の通知チャンネルに対応しています。
Terraform での設定
以降の Terraform コード例で共通で使用する通知チャンネルの定義です。
1resource "google_monitoring_notification_channel" "email" { 2 display_name = "Email - ops-team" 3 type = "email" 4 labels = { 5 email_address = "ops-team@example.com" 6 } 7}
1. ログベースのアラート
概要
最もシンプルなアラート方式です。ログエクスプローラで定義したフィルタに一致するログエントリが発生するたびに通知されます。
向いているケース:
- セキュリティ上重要なイベント(不正アクセスの試行など)
- 発生頻度が低いが見逃せない重大エラー
- 特定のメッセージやステータスコードの検知
制限事項:
- ポリシーごとに5分に1件のインシデントが上限
- ポリシーごとに1日最大20件のインシデント
- フォルダ・請求先アカウント・組織レベルのログは監視不可
- インシデントはデフォルト7日で自動クローズ
コンソールから作成する
- Logging > ログエクスプローラ を開く
- クエリエディタに以下のフィルタを入力して「クエリを実行」をクリック
1resource.type="cloud_run_revision" 2resource.labels.service_name="my-service" 3severity>=ERROR
- 結果を確認したら、ヘッダーの「アラートを作成」>「ログエントリに基づくアラートを作成」をクリック
- アラートの詳細を入力(アラート名: Cloud Run エラーログ検知、説明: 任意でアラートの目的を記載)
- 通知先にメールを追加
- 「保存」をクリック
Terraform で作成する
1resource "google_monitoring_alert_policy" "cloud_run_log_alert" { 2 display_name = "Cloud Run エラーログ検知" 3 combiner = "OR" 4 5 conditions { 6 display_name = "Cloud Run ERROR ログの検出" 7 condition_matched_log { 8 filter = <<-EOT 9 resource.type="cloud_run_revision" 10 AND resource.labels.service_name="my-service" 11 AND severity>=ERROR 12 EOT 13 } 14 } 15 16 notification_channels = [ 17 google_monitoring_notification_channel.email.name, 18 ] 19 20 alert_strategy { 21 notification_rate_limit { 22 period = "300s" 23 } 24 auto_close = "604800s" 25 } 26}
condition_matched_log がログベースのアラート専用のブロックです。alert_strategy の notification_rate_limit で通知間隔を制御できます(上記は5分間隔)。
2. ログベースの指標アラート
概要
ログからカスタム指標(メトリクス)を作成し、その指標に対して閾値ベースのアラートを設定する方式です。「5分間にエラーが10件以上」のような統計的な条件で通知したい場合に適しています。
設定は2ステップで行います:
- ログベースの指標を作成 — ログエントリを数値データに変換
- アラートポリシーを作成 — 指標に対して閾値を設定
コンソールから作成する
ステップ1:ログベースの指標を作成
- Logging > ログベースの指標 を開く
- 「指標を作成」をクリック
- 以下を設定(指標タイプ: カウンター、指標名: cloud-run-error-count)
1resource.type="cloud_run_revision" 2resource.labels.service_name="my-service" 3severity>=ERROR
- 「指標を作成」をクリック
ステップ2:アラートポリシーを作成
- Monitoring > アラート を開き、「ポリシーを作成」をクリック
- 「指標を選択」で logging.googleapis.com/user/cloud-run-error-count を選択
- トリガーの条件を設定(条件タイプ: Threshold(閾値)、閾値: 10(5分間に10件以上でアラート))
- 通知チャンネルにメールを追加して保存
Terraform で作成する
1# ログベースの指標 2resource "google_logging_metric" "cloud_run_error_count" { 3 name = "cloud-run-error-count" 4 filter = <<-EOT 5 resource.type="cloud_run_revision" 6 AND resource.labels.service_name="my-service" 7 AND severity>=ERROR 8 EOT 9 metric_descriptor { 10 metric_kind = "DELTA" 11 value_type = "INT64" 12 } 13} 14 15# 指標に対するアラートポリシー 16resource "google_monitoring_alert_policy" "cloud_run_metric_alert" { 17 display_name = "Cloud Run エラー率アラート" 18 combiner = "OR" 19 20 conditions { 21 display_name = "5分間のエラー数が10件を超過" 22 condition_threshold { 23 filter = "metric.type=\"logging.googleapis.com/user/${google_logging_metric.cloud_run_error_count.name}\" AND resource.type=\"cloud_run_revision\"" 24 comparison = "COMPARISON_GT" 25 threshold_value = 10 26 duration = "300s" 27 aggregations { 28 alignment_period = "300s" 29 per_series_aligner = "ALIGN_SUM" 30 } 31 } 32 } 33 34 notification_channels = [ 35 google_monitoring_notification_channel.email.name, 36 ] 37}
ログベースのアラートとの違いは、condition_threshold を使っている点です。duration と alignment_period で評価期間を指定し、threshold_value で閾値を設定します。
3. SQL ベースのアラート
概要
Log Analytics(ログ分析)を有効にした状態で、SQL クエリの結果に基づいてアラートを発行する最も高度な方式です。複数のログソースを結合した分析や、GROUP BY を使った集計など、柔軟な条件指定ができます。
前提条件: ログバケットで Log Analytics が有効化されている必要があります。
コンソールから作成する
- Logging > ログストレージ でログバケットの「Log Analytics をアップグレード」を有効化
- Logging > ログ分析 を開く
- SQL クエリを入力して「クエリを実行」で結果を確認
1SELECT 2 resource.labels.service_name AS service_name, 3 COUNT(*) AS error_count 4FROM 5 `PROJECT_ID.global._Default._AllLogs` 6WHERE 7 resource.type = 'cloud_run_revision' 8 AND severity >= 'ERROR' 9 AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 10 MINUTE) 10GROUP BY 11 1 12HAVING 13 error_count > 20
- クエリ結果が意図通りであれば、「アラートを作成」をクリック
- 評価間隔や通知先を設定して保存
この例では、10分間にエラーが20件を超えた Cloud Run サービスを検出します。PROJECT_ID は実際のプロジェクト ID に置き換えてください。
Terraform で作成する
Terraform では condition_sql ブロックを使って SQL ベースのアラートを定義できます。
1resource "google_monitoring_alert_policy" "cloud_run_sql_alert" { 2 display_name = "Cloud Run SQL ベースアラート" 3 combiner = "OR" 4 5 conditions { 6 display_name = "10分間のエラー数が20件を超過" 7 condition_sql { 8 query = <<-EOT 9 SELECT 10 resource.labels.service_name AS service_name, 11 COUNT(*) AS error_count 12 FROM 13 `PROJECT_ID.global._Default._AllLogs` 14 WHERE 15 resource.type = 'cloud_run_revision' 16 AND severity >= 'ERROR' 17 AND timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 10 MINUTE) 18 GROUP BY 19 1 20 HAVING 21 error_count > 20 22 EOT 23 minutes { 24 periodicity = 10 25 } 26 row_count_test { 27 comparison = "COMPARISON_GT" 28 threshold = "0" 29 } 30 } 31 } 32 33 notification_channels = [ 34 google_monitoring_notification_channel.email.name, 35 ] 36}
minutes.periodicity でクエリの評価間隔(分単位)を指定し、row_count_test でクエリ結果の行数に対する条件を設定します。
運用のポイント
アラートポリシーは「設定して終わり」ではなく、運用しながら調整していくものです。以下のポイントを意識すると、効果的な監視体制を構築できます。
フィルタは具体的に
フィルタが広すぎると大量の通知が届き、重要なアラートが埋もれるアラート疲れの原因になります。service_name や severity は必ず絞り込みましょう。
テスト通知を忘れずに
アラートポリシーを作成したら、意図的にエラーを発生させて通知が正しく届くか確認しましょう。通知チャンネルの設定ミスは意外と多いものです。
ポリシーの一時停止を活用する
メンテナンス時は、コンソールからアラートポリシーをワンクリックで無効化できます。作業完了後に有効に戻すのを忘れないようにしましょう。
3種類の使い分け
| やりたいこと | おすすめの方式 |
|---|---|
| 特定のエラーが出たらすぐ知りたい | ログベースのアラート |
| 一定期間のエラー数で判断したい | ログベースの指標アラート |
| 複雑な条件や複数ログの結合で判断したい | SQL ベースのアラート |
迷ったら、まずはログベースのアラートから始めて、必要に応じて指標ベースや SQL ベースに移行するのがおすすめです。
まとめ
本記事では、Cloud Logging の3種類のアラートポリシーについて、Cloud Run を題材に設定方法を解説しました。
- ログベースのアラート: 特定のログ出現を即座に検知。設定がシンプルで導入しやすい
- ログベースの指標アラート: ログをメトリクスに変換し、閾値で監視。統計的な判断が可能
- SQL ベースのアラート: SQL クエリによる高度な分析。複雑な条件も柔軟に対応
おすすめのフローは、まず GUI で試して動作を確認し、本番運用では Terraform でコード化することです。これにより設定の再現性が担保され、チームでのレビューも容易になります。
Cloud Run に限らず、GCE や Cloud SQL など他のサービスでも同様の仕組みでアラートを設定できるので、ぜひ自分のプロジェクトに合った監視設定を構築してみてください。
参考リンク
SHARE