画像処理系AIの Gemini 2.5 Flash Image と Cloud Vision API を比べてみる(Next.jsの実装例付き)

はじめに
2025年10月現在、この半年ほどでAIは驚くほど進化し、
特殊なプロンプトの技術がなくても求めている結果が得られるようになってきています。
その中でも最近とても驚かされたのが、Gemini 2.5 Flash Image(別名 Nano Banana)です。
これまで、画像の生成AIは多くありましたが、元画像を編集する場合、
主役のイメージが崩れてしまったり、生成に時間がかかったり、
環境を準備するために多くのコストがかかったりと、
製品で利用する場合には大きなハードルがありました。
Nano Banana ではこれらの問題を解消し、元画像の主役を破壊することなく、自然な編集が可能です。
また、特殊なプロンプトの技術も必要なく、何より1分かからないくらいの短時間で画像が生成されます。
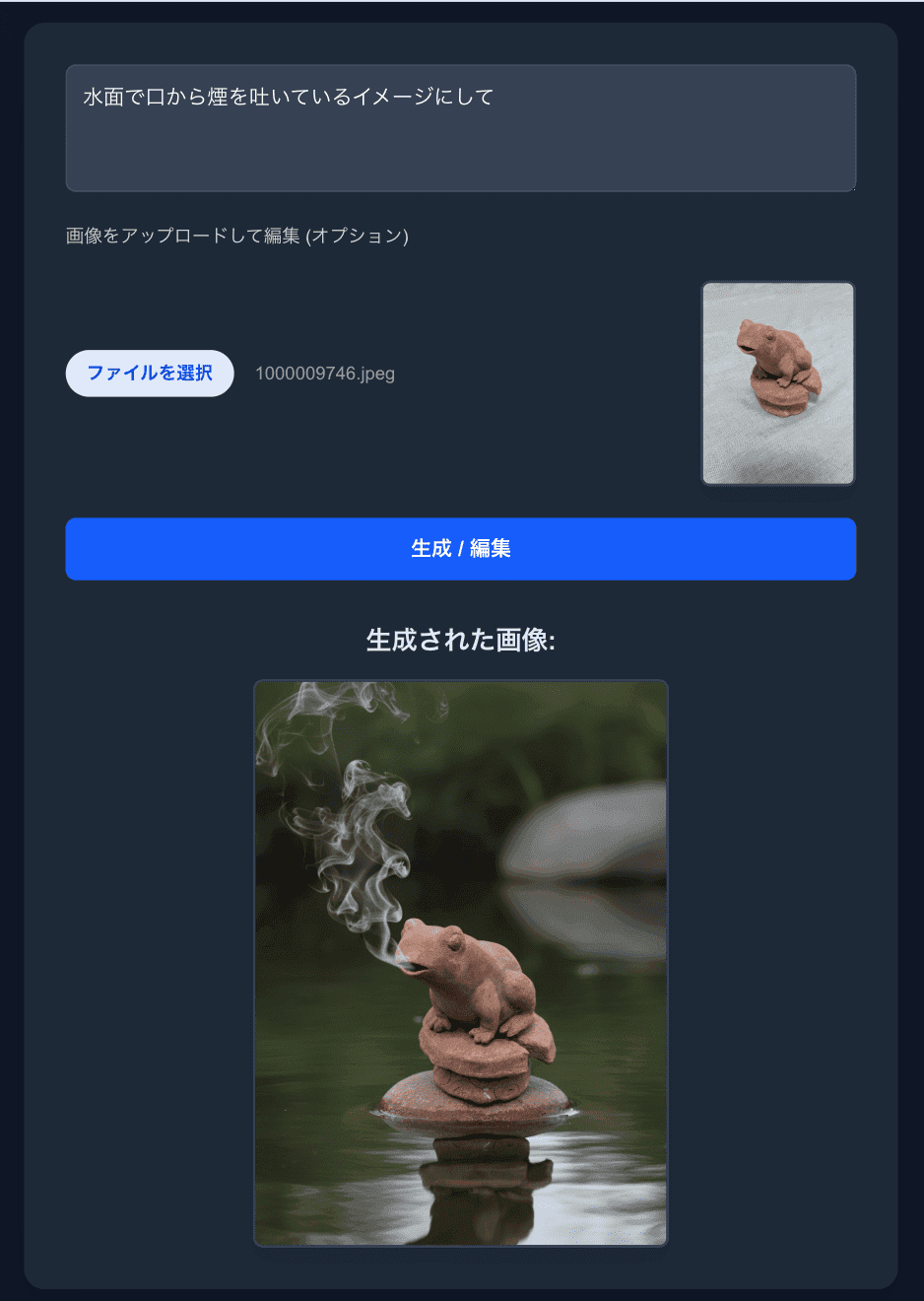
以下は、私が作った粘土細工の写真から Nano Bananaで別の場所に置かれたイメージを生成した例です。
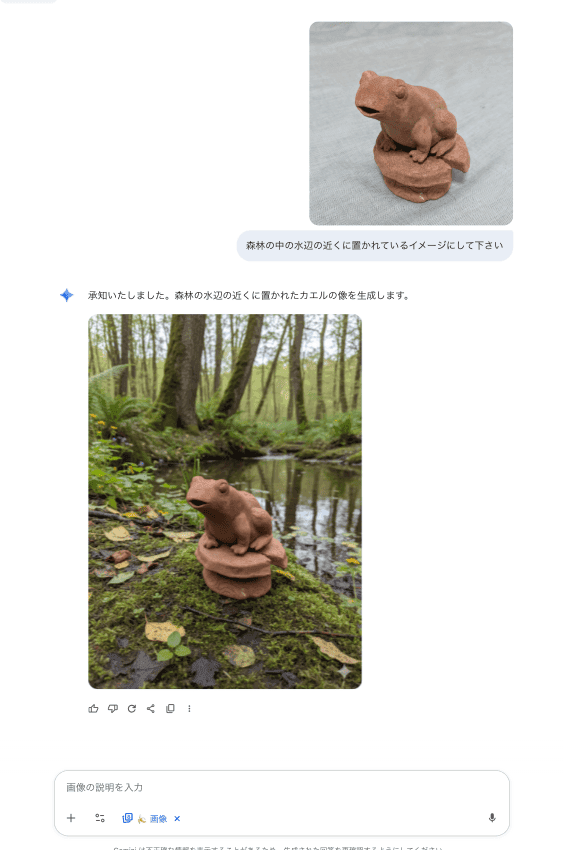
簡単なプロンプトで、オリジナルの特徴を保ちながらとても自然に画像が生成されました。生成にかかった時間はおよそ30秒ほどです。
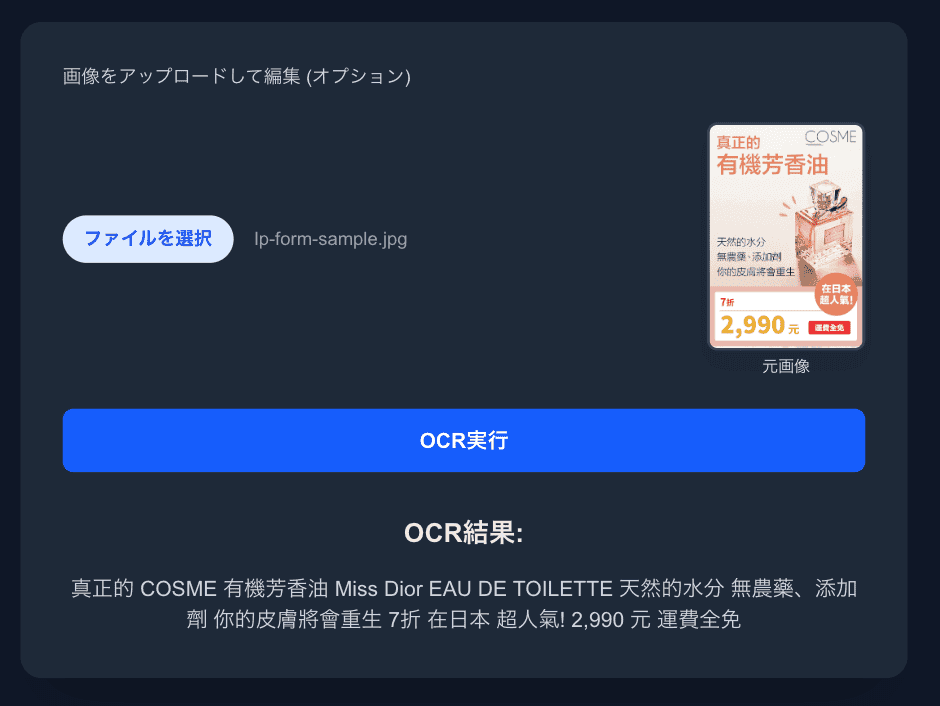
また、Gemini はテキスト認識も得意で、画像からテキストを読み取る用途でも高い精度を示します。
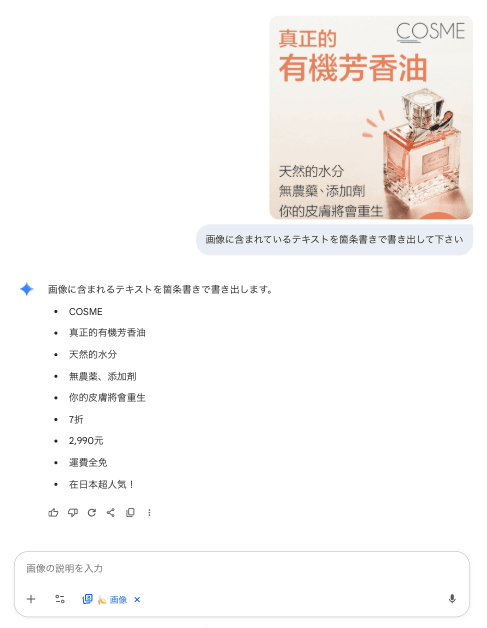
ただし、画像からテキストを抽出するだけであれば、画像解析に特化した Google Cloud Vision API の方がコスト面や座標情報などの出力面で優れています。用途に応じて使い分けると良いでしょう。
料金
※ 2025.10.1 時点の価格です
Gemini 2.5 Flash Image Preview
- 入力: $0.30/100万トークン
- 出力: 画像 1 枚あたり $0.039
先ほどの例では1枚あたり約3円でした
Cloud Vision API
- $1.50/1,000ユニット
1枚あたり約0.2円になります
料金的には Cloud Vision API の方が圧倒的に安くなりますので、
テキストの抽出などであれば、Cloud Vision API を使った方がお得です。
Next.jsでの実装例
前提条件(修正版)
- Node.js と Next.js(app router)を利用していること。Server Actions をサポートする Next.js のバージョン(例: Next.js 14 以降)を想定しています。 - Server Actions('use server')はサーバー側で実行される機能です。クライアント側の処理と混同しないよう注意してください。 - 必要なパッケージ例: - Gemini 用: @google/genai(使用するライブラリに応じて名称や初期化方法は変わります) - Cloud Vision 用: @google-cloud/vision - パッケージインストール例: - npm install @google/genai @google-cloud/vision - 認証と環境変数(明確化): - Gemini: サンプルでは GEMINI_API_KEY を例示していますが、利用するクライアントライブラリによって環境変数名(例: GOOGLE_API_KEY 等)が異なる場合があります。ライブラリのドキュメントを必ず確認してください。 - Cloud Vision: サービスアカウントの JSON キーを使う場合は、GOOGLE_APPLICATION_CREDENTIALS にパスを指定するか、ADC(Application Default Credentials)を利用してください。 - 例: export GOOGLE_APPLICATION_CREDENTIALS="/path/to/service-account.json"実行上の注意(修正版)
- Server Actions はサーバー環境で実行することを前提としています。ブラウザ側の File オブジェクトをそのまま扱う実装は環境依存になるため、Edge ランタイム等での挙動に注意してください。 - 画像サイズや MIME タイプに制約がある場合が多いので、アップロード前にリサイズ・圧縮を行うと安定します。 - 本番運用では、認証情報の保護、アップロードファイルの検証(MIME/type、サイズ、ウイルス検査等)、API 利用制限(レートリミットやコスト)を必ず設計してください。Gemini 2.5 Flash Image Preview
まず、GeminiのAPIキーのページで、APIキーを取得し、
.env ファイルに取得したAPIキーを書き込んでおきます。
.env
1GEMINI_API_KEY=<取得したAPIキー>
次に Next.js のServer Actions で Gemini 2.5 Flash Image Preview を呼び出し、 プロンプトと画像から、画像を編集する処理を作成します。
app/actions.ts
1'use server'; 2 3import { GoogleGenAI } from "@google/genai"; 4 5// APIクライアントを初期化します。 6// この方法は、環境変数 'GOOGLE_API_KEY' が設定されていることを前提とします。 7const ai = new GoogleGenAI({}); 8 9// APIに渡すコンテンツのパーツの型 10type ContentPart = { text: string } | { inlineData: { mimeType: string; data: string } }; 11 12export async function generateOrEditImageAction(formData: FormData): Promise<{ 13 imageData?: string; // Base64エンコードされた画像データ 14 error?: string; 15}> { 16 const prompt = formData.get('prompt'); // フォームからプロンプトを取得 17 const imageFile = formData.get('image'); // フォームから画像ファイルを取得 18 19 try { 20 // APIに送信するコンテンツを構築 21 const contents: ContentPart[] = [ 22 { text: String(prompt) } 23 ]; 24 25 // 画像ファイルがアップロードされている場合の処理 26 if (imageFile instanceof File && imageFile.size > 0) { 27 const imageBuffer = Buffer.from(await imageFile.arrayBuffer()); 28 contents.push({ 29 inlineData: { 30 mimeType: imageFile.type, 31 data: imageBuffer.toString("base64"), 32 }, 33 }); 34 } 35 36 // APIを呼び出し 37 const response = await ai.models.generateContent({ 38 model: "gemini-2.5-flash-image-preview", 39 contents, // 構築したコンテンツを渡す 40 }); 41 42 // レスポンスをループで処理し、最初の画像データを取得する 43 for (const part of response.candidates[0].content.parts) { 44 if (part.inlineData) { 45 // 画像データが見つかったら、それを返して処理を終了 46 return { imageData: part.inlineData.data }; 47 } 48 } 49 50 // 画像データがレスポンスに含まれていなかった場合 51 return { error: "レスポンスに画像データが含まれていませんでした" }; 52 53 } catch (error) { 54 console.error("API Error:", error); 55 return { error: "APIリクエスト中にエラーが発生しました" }; 56 } 57}
最後に、ページを作成し、そこで先ほどの Server Action を呼び出します。
nano-banana/page.tsx
1'use client'; 2 3import { useRef, useState } from 'react'; 4import { useFormStatus } from "react-dom"; 5import { generateOrEditImageAction } from '../actions'; // Server Actionをインポート 6 7const SubmitButton = () => { 8 const { pending } = useFormStatus(); 9 return ( 10 <button 11 type="submit" 12 disabled={pending} 13 className="w-full bg-blue-600 hover:bg-blue-700 text-white font-bold py-3 px-4 rounded-lg transition-colors disabled:opacity-50 disabled:cursor-not-allowed" 14 > 15 {pending ? '生成中...' : '生成 / 編集'} 16 </button> 17 ); 18}; 19 20export default function Page() { 21 // 状態管理用のフック 22 const [prompt, setPrompt] = useState<string>(""); 23 const [generatedImage, setGeneratedImage] = useState<string | null>(null); 24 const [uploadedImage, setUploadedImage] = useState<string | null>(null); 25 const [error, setError] = useState<string | null>(null); 26 const fileInputRef = useRef<HTMLInputElement | null>(null); 27 28 const handlePromptChange = (e: React.ChangeEvent<HTMLTextAreaElement>) => { 29 setPrompt(e.target.value); 30 }; 31 32 const handleFileChange = async () => { 33 if (fileInputRef.current?.files?.[0]) { 34 const reader = new FileReader(); 35 reader.onloadend = () => { 36 setUploadedImage(reader.result as string); 37 }; 38 reader.readAsDataURL(fileInputRef.current.files[0]); 39 } 40 }; 41 42 // フォーム送信時の処理 43 async function handleFormSubmit(formData: FormData) { 44 setUploadedImage(null); 45 setGeneratedImage(null); 46 setError(null); 47 48 // Server Actionを呼び出し、結果を取得 49 const result = await generateOrEditImageAction(formData); 50 51 if (result.imageData) { 52 setGeneratedImage(`data:image/png;base64,${result.imageData}`); 53 } else if (result.error) { 54 setError(result.error); 55 } 56 } 57 58 return ( 59 <main className="flex items-center justify-center min-h-screen bg-gray-900 text-white p-4"> 60 <div className="w-full max-w-2xl mx-auto"> 61 <div className="bg-gray-800 shadow-2xl rounded-2xl p-8"> 62 {/* Server Actionを呼び出すフォーム */} 63 <form action={handleFormSubmit} className="flex flex-col gap-6"> 64 {/* プロンプト入力エリア */} 65 <textarea 66 name="prompt" 67 rows={3} 68 className="w-full p-3 bg-gray-700 rounded-lg border border-gray-600 focus:ring-2 focus:ring-blue-500 focus:outline-none transition-all" 69 placeholder="例: 月面でくつろぐ、サイバーパンク風の猫" 70 required 71 value={prompt} 72 onChange={handlePromptChange} 73 /> 74 75 {/* 画像アップロードエリア */} 76 <div> 77 <label htmlFor="image-upload" className="block mb-2 text-sm font-medium text-gray-300"> 78 画像をアップロードして編集 (オプション) 79 </label> 80 <div className="flex items-center gap-4"> 81 <input 82 ref={fileInputRef} 83 type="file" 84 name="image" 85 id="image-upload" 86 accept="image/png, image/jpeg" 87 className="block w-full text-sm text-gray-400 file:mr-4 file:py-2 file:px-4 file:rounded-full file:border-0 file:text-sm file:font-semibold file:bg-blue-100 file:text-blue-700 hover:file:bg-blue-200" 88 onChange={handleFileChange} 89 /> 90 {uploadedImage && ( 91 <figure className="flex-shrink-0 text-center"> 92 <img 93 width="120" 94 src={uploadedImage} 95 alt="Uploaded preview" 96 className="mt-4 max-w-full rounded-lg shadow-lg border-2 border-gray-700" 97 /> 98 </figure> 99 )} 100 </div> 101 </div> 102 103 {/* 送信ボタン */} 104 <SubmitButton /> 105 </form> 106 107 {/* 結果表示エリア */} 108 <div className="mt-8 text-center"> 109 {error && ( 110 <p className="text-red-400 bg-red-900/50 p-3 rounded-lg"> 111 エラー: {error} 112 </p> 113 )} 114 115 {!!generatedImage && ( 116 <div className="mt-4"> 117 <h2 className="text-xl font-semibold mb-4 text-gray-200">生成された画像:</h2> 118 <img 119 src={generatedImage} 120 width="480" 121 alt="Generated or edited" 122 className="max-w-full mx-auto rounded-lg shadow-lg border-2 border-gray-700" 123 /> 124 </div> 125 )} 126 </div> 127 </div> 128 </div> 129 </main> 130 ); 131}
実行結果
補足説明
- contents の構成:
- { text: string } はテキストプロンプト。
- { inlineData: { mimeType, data } } は Base64 エンコードした画像を埋め込む形式。返却される画像も base64 形式が多いため、表示する際は data:image/xxx;base64, を付与して data URI として扱います。
- レスポンス処理:
- generateContent の戻り値は候補(candidates)として複数返る場合があります。必要に応じて候補の選択やエラーチェックを行ってください。
- トラブルシューティング:
- 画像が返らない場合は response をログ出力してパート構成を確認してください。
- 認証エラーや権限不足は、環境変数やサービスアカウントの設定ミスが原因になりやすいです。
Cloud Vision API
Cloud Vision API を使う場合は、以下を参照して認証を通して下さい。
次に、Server Actions で Cloud Vision API を呼び出し、画像からテキストを抽出する処理を作成します。 app/actions.ts
1'use server'; 2 3// ご提示のコードに合わせてライブラリとクラス名を変更 4import { ImageAnnotatorClient } from '@google-cloud/vision'; 5 6// APIクライアントを初期化します。 7// この方法は、環境変数 'GOOGLE_API_KEY' が設定されていることを前提とします。 8const visionClient = new ImageAnnotatorClient(); 9 10export async function ocrAction(formData: FormData): Promise<{ 11 text?: string; // 抽出されたテキスト 12 error?: string; 13}> { 14 const imageFile = formData.get('image'); // フォームから画像ファイルを取得 15 16 try { 17 const imageBuffer = Buffer.from(await imageFile.arrayBuffer()); 18 19 // 画像の内容を解析して、テキストを抽出 20 const [result] = await visionClient.textDetection(imageBuffer); 21 22 const detections = result.textAnnotations; 23 if (!detections || detections.length === 0) { 24 return { error: "画像からテキストが検出されませんでした" }; 25 } 26 27 // 最初の要素に全文が含まれている 28 const extractedText = detections[0].description || ""; 29 return { text: extractedText }; // Base64エンコードして返す 30 31 } catch (error) { 32 console.error("Vision API Error:", error); 33 return { error: "画像解析中にエラーが発生しました" }; 34 } 35 36 // ここでマスク処理を実装します。現在はダミーのレスポンスを返します。 37 return { error: "マスク処理はまだ実装されていません" }; 38}
ここでは画像解析の結果から概要だけ取得していますが、座標などを含めた詳細な情報も取得可能です。
ページは先ほどの Gemini の例とほぼ同じですので、ご覧になりたい場合はクリックで開いて下さい。
詳細な情報を取得する例
1'use client'; 2 3import { useEffect, useRef, useState } from 'react'; 4import { useFormStatus } from "react-dom"; 5import { ocrAction } from '../actions'; // Server Actionをインポート 6 7const SubmitButton = () => { 8 const { pending } = useFormStatus(); 9 return ( 10 <button 11 type="submit" 12 disabled={pending} 13 className="w-full bg-blue-600 hover:bg-blue-700 text-white font-bold py-3 px-4 rounded-lg transition-colors disabled:opacity-50 disabled:cursor-not-allowed" 14 > 15 {pending ? '生成中...' : 'OCR実行'} 16 </button> 17 ); 18}; 19 20export default function HomePage() { 21 // 状態管理用のフック 22 const [ocrText, setOcrText] = useState<string | null>(null); 23 const [uploadedImage, setUploadedImage] = useState<string | null>(null); 24 const [error, setError] = useState<string | null>(null); 25 const fileInputRef = useRef<HTMLInputElement | null>(null); 26 27 const handleFileChange = async () => { 28 if (fileInputRef.current?.files?.[0]) { 29 const reader = new FileReader(); 30 reader.onloadend = () => { 31 setUploadedImage(reader.result as string); 32 }; 33 reader.readAsDataURL(fileInputRef.current.files[0]); 34 } 35 }; 36 37 // フォーム送信時の処理 38 async function handleFormSubmit(formData: FormData) { 39 setUploadedImage(null); 40 setOcrText(null); 41 setError(null); 42 43 const result = await ocrAction(formData); 44 45 if (result.text) { 46 setOcrText(result.text); 47 } else if (result.error) { 48 setError(result.error); 49 } 50 } 51 52 return ( 53 <main className="flex items-center justify-center min-h-screen bg-gray-900 text-white p-4"> 54 <div className="w-full max-w-2xl mx-auto"> 55 <div className="bg-gray-800 shadow-2xl rounded-2xl p-8"> 56 {/* Server Actionを呼び出すフォーム */} 57 <form action={handleFormSubmit} className="flex flex-col gap-6"> 58 {/* 画像アップロードエリア */} 59 <div> 60 <label htmlFor="image-upload" className="block mb-2 text-sm font-medium text-gray-300"> 61 画像をアップロードして編集 (オプション) 62 </label> 63 <div className="flex items-center gap-4"> 64 <input 65 ref={fileInputRef} 66 type="file" 67 name="image" 68 id="image-upload" 69 accept="image/png, image/jpeg" 70 className="block w-full text-sm text-gray-400 file:mr-4 file:py-2 file:px-4 file:rounded-full file:border-0 file:text-sm file:font-semibold file:bg-blue-100 file:text-blue-700 hover:file:bg-blue-200" 71 onChange={handleFileChange} 72 /> 73 {uploadedImage && ( 74 <figure className="flex-shrink-0 text-center"> 75 <img 76 width="120" 77 src={uploadedImage} 78 alt="Uploaded preview" 79 className="mt-4 max-w-full rounded-lg shadow-lg border-2 border-gray-700" 80 /> 81 <figcaption className="text-xs mt-1 text-gray-200">元画像</figcaption> 82 </figure> 83 )} 84 </div> 85 </div> 86 87 {/* 送信ボタン */} 88 <SubmitButton /> 89 </form> 90 91 {/* 結果表示エリア */} 92 <div className="mt-8 text-center"> 93 {error && ( 94 <p className="text-red-400 bg-red-900/50 p-3 rounded-lg"> 95 エラー: {error} 96 </p> 97 )} 98 99 {!!ocrText && ( 100 <div className="mt-4"> 101 <h2 className="text-xl font-semibold mb-4 text-gray-200">OCR結果:</h2> 102 <p className="text-gray-300">{ocrText}</p> 103 </div> 104 )} 105 </div> 106 </div> 107 </div> 108 </main>
実行結果
Cloud Vision の補足
- 認証: 開発時はサービスアカウント JSON を使い、GOOGLE_APPLICATION_CREDENTIALS を設定するのが手軽です。本番では GCP の IAM 設定や環境に応じた最適な認証方式を採用してください。
- 画像入力: Buffer、base64、または GCS 参照のいずれかを渡せます。この記事の例は Buffer を直接渡す方法です。
- 詳細情報: 領域(座標)情報やページ分割が必要な場合は result.fullTextAnnotation や pages/blocks/paragraphs/words を参照してください。
- エラー対策: ネットワークやレート制限を考慮してリトライやバックオフを実装することをお勧めします。
まとめ
1つのAPIを呼び出すだけで、画像の生成や編集ができる Gemini 2.5 Flash Image や Vision API はとても強力だと感じます。
特に、Gemini 2.5 Flash Image はこの半年の進化としては驚異的ですので、今後の展開が楽しみです。
AIを使った画像の処理は、今後はもっと身近なものになっていくでしょう。
参考
Author Profile
SHARE