2024/06/13
Looker Studioでテストカバレッジを可視化する
はじめに
Looker Studio は、様々なデータソースからデータを収集し、使いやすいダッシュボードを作成できるツールです。今回は、Looker Studio で Jest で出力されたテストカバレッジを可視化する方法を紹介します。本記事は、 Jest を用いてテストコードを作成し、カバレッジレポートの生成経験をお持ちの方向けです。
Jest のカバレッジレポートを CSV 形式に変換する
jest コマンドを使用して、テストを実行しカバレッジレポートを生成します。
1$ npx jest --coverage --coverageReporters=json-summary --collectCoverageFrom="src/**/*.js" 2 PASS src/sum.test.js 3 ✓ adds 1 + 2 to equal 3 (2 ms) 4 5Test Suites: 1 passed, 1 total 6Tests: 1 passed, 1 total 7Snapshots: 0 total 8Time: 0.653 s 9Ran all test suites. 10 11$ npx -y jest-coverage-to-csv coverage/coverage-summary.json 12Conversion to CSV success!
- jest コマンドに オプションをつけてテストコードが存在しないソースコードもカバレッジに含まれるようにします。このようにすることでソースコード全体のカバレッジが確認できるようになります
1--collectCoverageFrom="src/**/*.js" - BigQueryに取り込むためにCSV形式のデータが必要です。 jest のカバレッジレポートの出力形式はいくつかありますが、CSV形式はサポートされていません。そのため、jest コマンドに をつけて一旦json形式で出力後、 jest-coverage-to-csv を使ってCSV形式に変換します
1--coverageReporters=json-summary
生成された coverage/coverage-summary.csv ファイルは、後で使用するために保存しておきます。
今回は日毎のカバレッジの推移を確認したいので下記の内容の2日分のファイルを日付付きのファイル名にリネームして保存したとして進めます。
1coverage/coverage-summary_2024-06-12.csv 2coverage/coverage-summary_2024-06-13.csv
6/12時点のテストカバレッジ
1----------|---------|----------|---------|---------|------------------- 2File | % Stmts | % Branch | % Funcs | % Lines | Uncovered Line #s 3----------|---------|----------|---------|---------|------------------- 4All files | 50 | 100 | 50 | 50 | 5 sub.js | 0 | 100 | 0 | 0 | 2-4 6 sum.js | 100 | 100 | 100 | 100 | 7----------|---------|----------|---------|---------|------------------- 8Test Suites: 1 passed, 1 total 9Tests: 1 passed, 1 total 10Snapshots: 0 total 11Time: 0.362 s, estimated 1 s
6/13時点のテストカバレッジ
1----------|---------|----------|---------|---------|------------------- 2File | % Stmts | % Branch | % Funcs | % Lines | Uncovered Line #s 3----------|---------|----------|---------|---------|------------------- 4All files | 100 | 100 | 100 | 100 | 5 sub.js | 100 | 100 | 100 | 100 | 6 sum.js | 100 | 100 | 100 | 100 | 7----------|---------|----------|---------|---------|------------------- 8 9Test Suites: 2 passed, 2 total 10Tests: 2 passed, 2 total 11Snapshots: 0 total 12Time: 0.633 s, estimated 1 s
CSVファイルをBigQueryに取り込む
gcloud CLI に含まれている BigQuery 用のコマンドラインツールである bq コマンドを使用して、先ほど保存した CSV ファイルを BigQuery のテーブルとして取り込みます。
1$ bq load --source_format CSV --skip_leading_rows 1 --replace=true coverage_sample.report_2024-06-12 ./coverage/coverage-summary_2024-06-12.csv filename:STRING,statements_ratio:FLOAT,statements_detail:STRING,branches_ratio:FLOAT,branches_detail:STRING,functions_ratio:FLOAT,functions_detail:STRING,lines_ratio:FLOAT,lines_detail:STRING 2Upload complete. 3Waiting on bqjob_rc3c57bf6bd57867_000001900f7f57cc_1 ... (0s) Current status: DONE 4 5$ bq load --source_format CSV --skip_leading_rows 1 --replace=true coverage_sample.report_2024-06-13 ./coverage/coverage-summary_2024-06-13.csv filename:STRING,statements_ratio:FLOAT,statements_detail:STRING,branches_ratio:FLOAT,branches_detail:STRING,functions_ratio:FLOAT,functions_detail:STRING,lines_ratio:FLOAT,lines_detail:STRING 6Upload complete. 7Waiting on bqjob_r7ca5c1fd8e62ebaf_000001900f7f98e3_1 ... (0s) Current status: DONE
- あらかじめ gcloud コマンドで BigQuery にデータを書き込める権限があるアカウントでログインしている必要があります
- 取り込み先のデータセット、今回の例では の.より前の部分は、あらかじめ作成しておく必要があります
1coverage_sample.report_2024-06-12 - CSVのヘッダーのカラム名にスペースが含まれているため、スキーマの自動認識機能は使用せず、bq コマンドのオプションとして指定します()
1statements_ratio:FLOAT,statements_detail:STRING,branches_ratio:FLOAT,branches_detail:STRING,functions_ratio:FLOAT,functions_detail:STRING,lines_ratio:FLOAT,lines_detail:STRING
処理が完了してDONEと表示されたら、BigQuery コンソールでテーブルが確認できます。
BigQuery コンソール上でワイルドカードテーブルを使った View を作成する
BigQuery のコンソールにアクセスすると先程取り込んだ2つのテーブルにテストカバレッジ情報が取り込まれていることが確認できます。
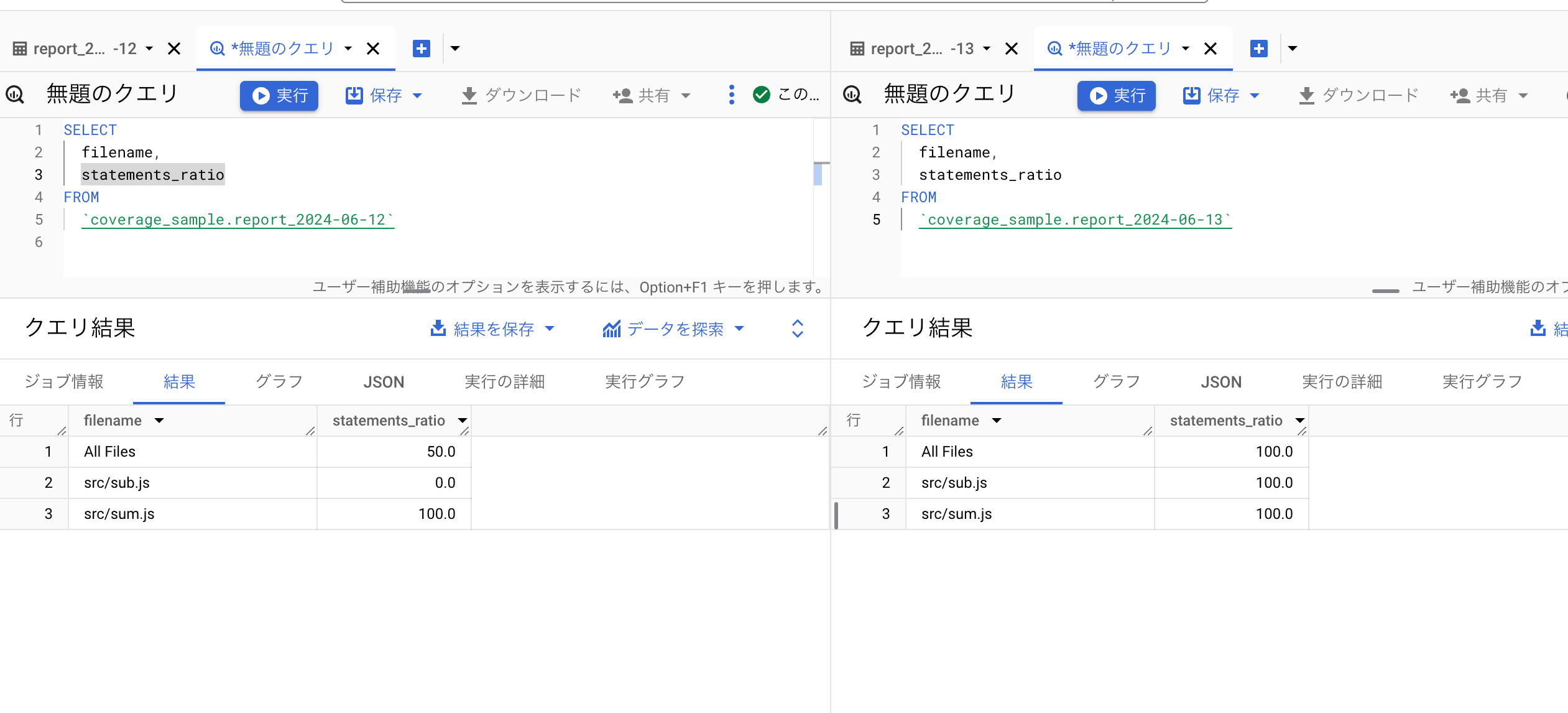
下記の SQL をコンソール上で実行して2つのテーブルをまとめた View を作成します。
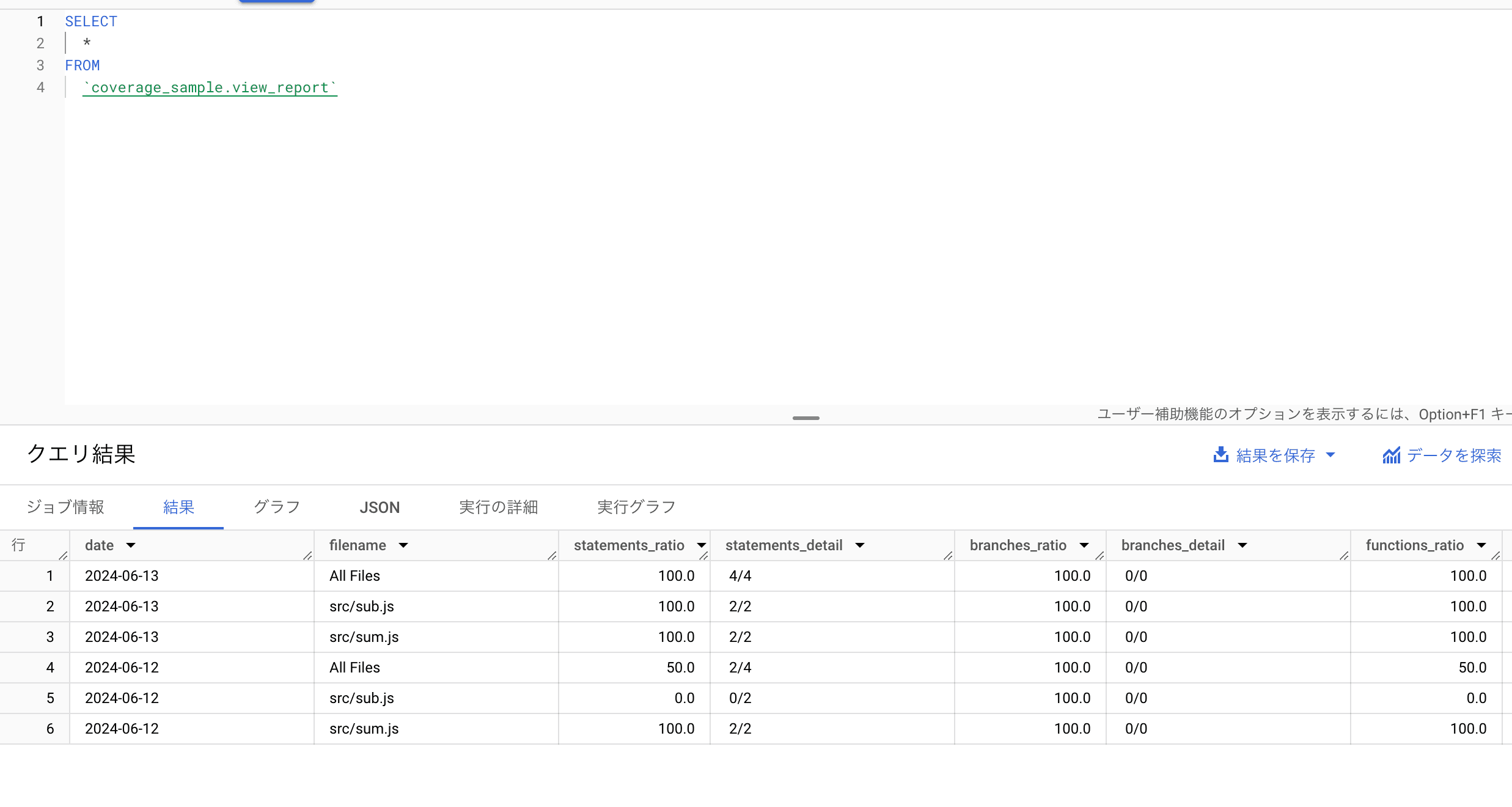
1CREATE VIEW 2 `coverage_sample.view_report` AS ( 3 SELECT 4 _TABLE_SUFFIX AS date, 5 * 6 FROM 7 `coverage_sample.report_*`)
- From 句に*を指定するワイルドカードテーブル機能を使うことで複数のテーブルを1つの View にまとめられます
- このままだとどの日付のデータなのかが区別つかなくなるので、_TABLE_SUFFIX 疑似列を使ったカラムを追加します。_TABLE_SUFFIX にはワイルドカードにマッチした文字列、ここではと
12024-06-12が入ります。このように設定しておくことで後日、12024-06-13のデータが追加されても自動で View に追記することができます12024-06-14
Looker Studio でグラフや表を作成する
https://lookerstudio.google.com/reporting にアクセスして新しいレポートを作成します。
データに接続タブで BigQuery を選択して先程のデータセットの View を選択します。
空のダッシュボードが作成されるので、右側のグラフ→設定タブで
1ディメンション:date 2指標:statements_ratio 3並べ替え:dateで昇順 4フィルター:All Files
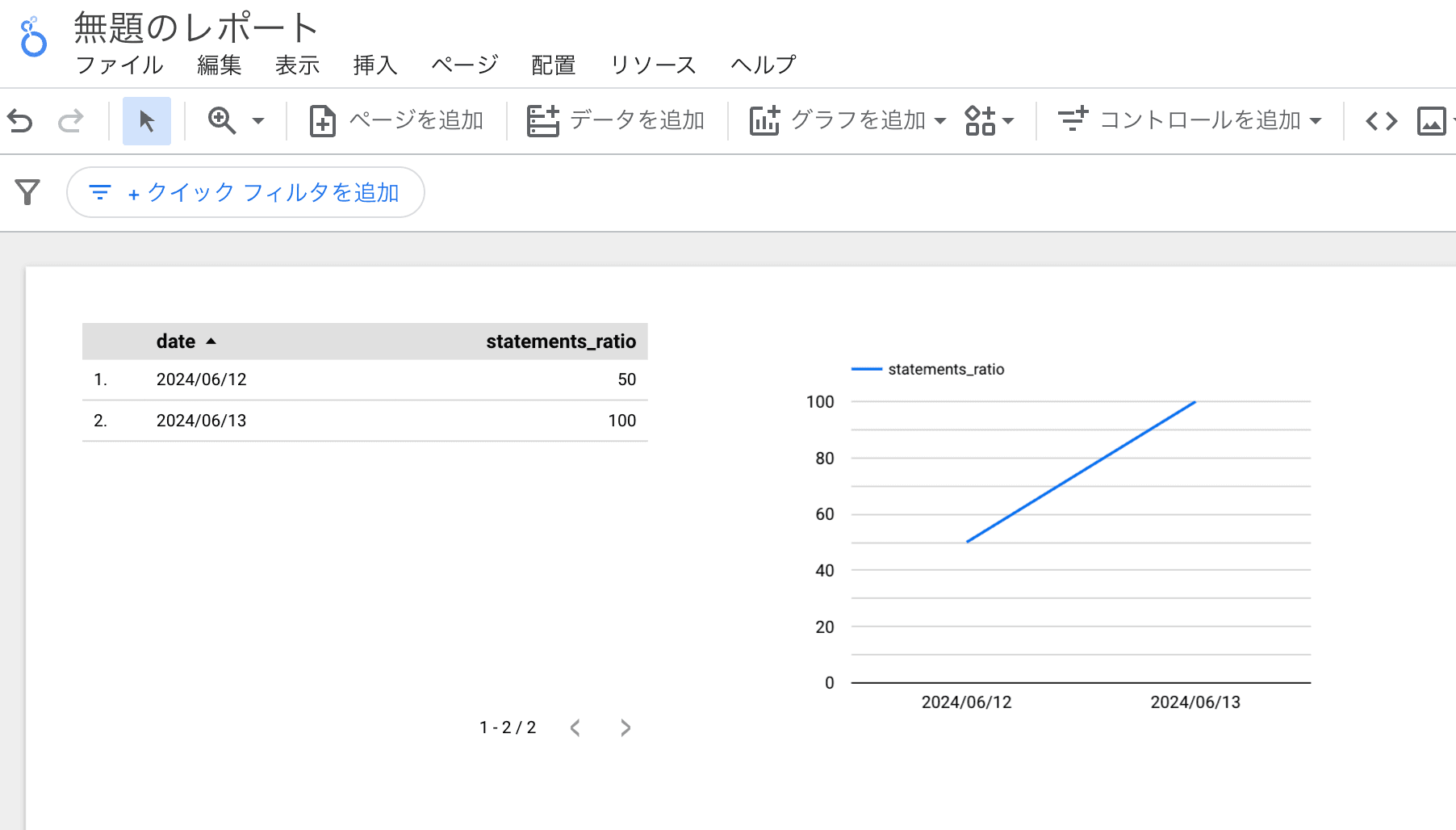
と選択すると、日毎のステートメントカバレッジの%の表が作成されます。 次に表をコピーしてグラフを作成します。選択した状態で右側のグラフのプルダウンで表やグラフの種類の変更ができます。今回は折れ線グラフを選択してみます。
下記のような表とグラフでテストカバレッジの日毎の推移を確認できるダッシュボードが作成できました。
まとめ
Jest のカバレッジレポートを集計可能な形式に変換するところが苦労しましたが、 BigQuery に取り込むことができれば表やグラフで可視化することが簡単にできることがわかりました。
今回の記事では説明できませんでしたが、カバレッジレポートを取得して BigQuery に取り込むところまでを GitHub Actions で実行するようにすれば、自動で新しい日毎のデータが取り込めるようになります。常に最新のカバレッジを確認できる状態を維持することで、チームメンバーのテストコードを書く意識が高まると思います。
みなさまのプロジェクトでも是非活用してみてください。
参考リンク
Author Profile

SHARE