ビッグデータ紹介

前略
今の時代で、「データの大爆発」て呼ばされている。
ギガバイトも満足されていない。Google毎日検索するデータ量は10PB(2015のデータ)。
もし全部MySQLに使えばサーバの検索効率はとっても低い
MySQLは同時にデータを処理する量はギガ単位 (1GB)
=
この量には一日終わらない。
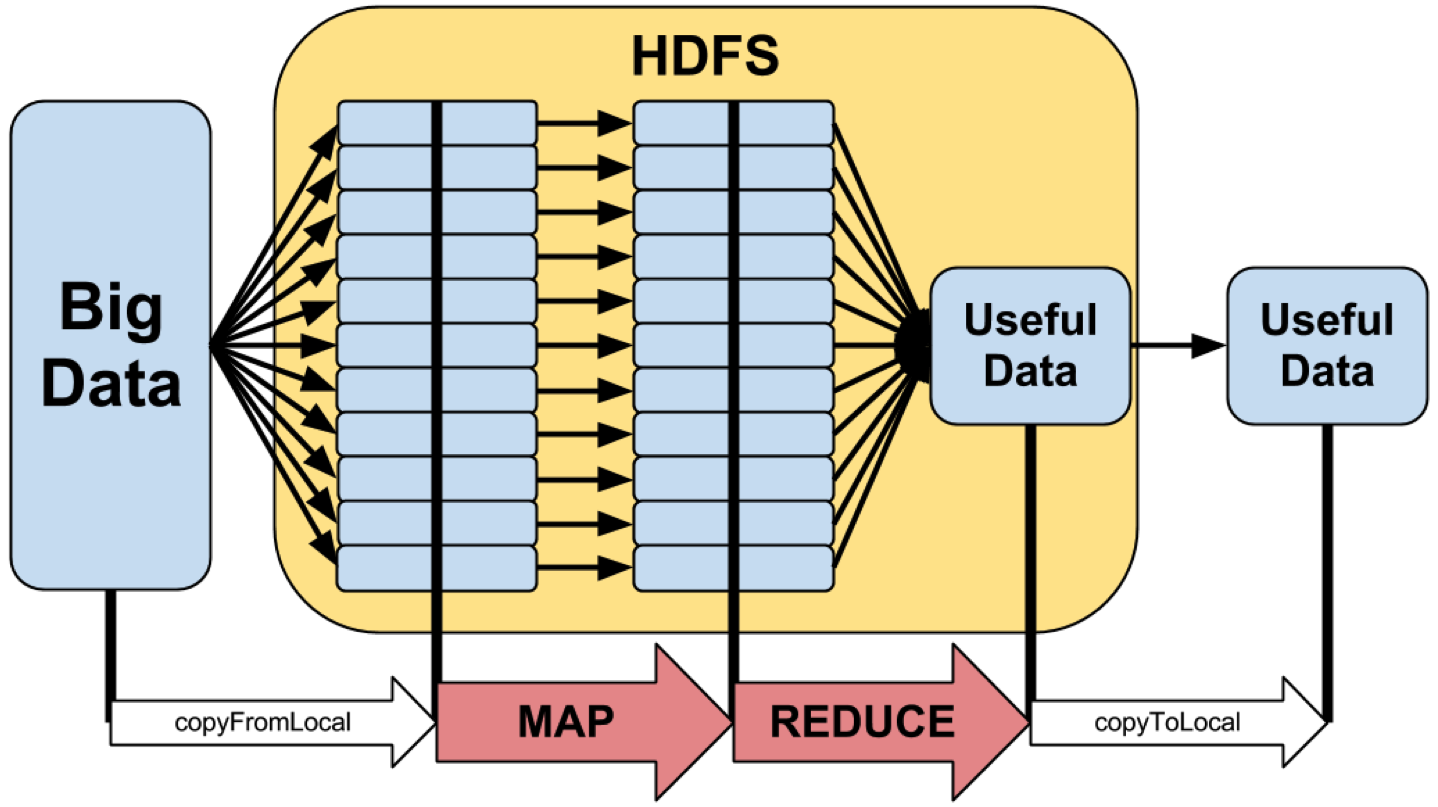
Hadoopに使え

HadoopはNON-SQLで呼ばれる。
SQLでStructured Query Language(構造的な言語)で、NON-SQLは「構造無し」の意味で
全部プログラム言語に運用しでいます。
原理は:
例(文字数カウント)
データ
|
1 2 3 | AABBDDC BBBCCAA BDHHAA |
Hadoop Node Aさん: (key =A ,1)(key =A ,1)(key =B ,1)(key =B ,1)(key =D ,1)(key =D ,1)(key =C,1)
Hadoop Node Bさん: (key =B ,1)(key =B ,1)(key =B ,1)(key =C ,1)(key =C ,1)(key =A,1)(key =A,1)
Hadoop Node Cさん: (key =B ,1)(key =D ,1)(key =H ,1)(key =H ,1)(key =A,1)(key =A,1)
最後の親に 子供達の記録を整理します
| 単語 | 単語数 |
| A | 6 |
| B | 6 |
| C | 3 |
| D | 3 |
| H | 2 |
このプロセスは「マップ」と「レデゥース」を呼ばれる。
でも、色々な欠点がある
- 全部プログラムで処理します。
- 「SELETE」みたいの命令全然ない(pigで命令を作る)
- 今まで、SQLに上手のプログラマーに好きにならない
- データ量少ない場合、遅い
- 面倒です(データベースに呼ばない)
RedShiftの紹介
Resdshiftはアマゾン開発されたたくさんSQL使えるなビッグデータ
![]()
原理は
Hadoopに似ている

データのストア方法はテーブルが
テーブル中に探すのは列単位です。(MySQLは行単位)
| 単語 | A | B | C | D | H |
テーブル定義: 「単語」と「単語数」はテーブル「文字数カウント」中に
| 単語数 | 6 | 6 | 3 | 3 | 2 |
Hadoop VS RedShift
| Hadoop | RedShift | |
| データ処理量 | PB | TB |
| スービド(TBデータ) | 速 | |
| スービド(PBデータ) | 速 | |
| プログラム言語 | 必要 | いらない |
| SQL | 使えない | 使える |
| 他 | 無料 | 有料 |
| ローカルMySQL連携できる | クラウド端末
処理するデータAWSにアップロード 結果データAWSからアップロード |
Author Profile

スターフィールド編集部
SHARE